High Availability (HA) and Disaster Recovery (DR)
The HA+DR concepts
High Availability, can be classified into two categories: High Availability of Hardware and High Availability of Application.
In High Availability Hardware, there is a heartbeat connection between the hardware components, assuring senhasegura turned to other hardware in case one of them suffers unavailability. This architecture was designed to minimize interruptions in senhasegura caused by hardware failures, providing continuity of services through high redundancy components.
Disaster recovery involves a set of policies and procedures that allow the recovery of the infrastructure in case of disaster, natural or man-made. It enables the redefinition of senhasegura resources in an alternative environment when it is not possible to recover the main environment in a reasonable period of time.
It is possible to implement the senhasegura architecture using:
- PAM Crypto Appliances running into on-premises datacenters;
- PAM Virtual Appliances running into on-premises datacenters;
- PAM Virtual Appliances running into cloud providers;
Replication technologies
There is many replication layers into senhasegura architecture to grant that all data will be available into all senhasegura ' instances.
Native database replication
senhasegura uses MariaDB Galera Cluster to grant database data replication, configured by default to support high latency networks;
File system replication using rsync
All instances will echo its files between all cluster members;
Kernel layer replication
When working with PAM Crypto Appliances, you also have a DRBD implemented;
Hot-Spare features and self-made Load balancer
senhasegura instances has monitoring and administrative URLs to monitor its status that can be used by load-balancers to automatically switch instances into a unavailability scenario.
You can use a proprietary load-balancer or acquire the senhasegura Load-balancer into your cluster scenario. See more at senhasegura Load-balancer manual.
Administrative URLs are explained better at section hotspare section of this manual.
Active-Passive
You can implement the Active-Passive schema using:
- Two PAM Virtual Appliances: Failover is done manually with synchronous automatic synchronization. In case of failure, the contingency environment will enter read-only mode, waiting for the manual failover to be done by the user or load-balancer rules;
- Two PAM Crypto Appliances: Devices have a heartbeat connection for fault detection and their own synchronization cables. Thus, when it is necessary for one device to assume the role of the other, the process is automatic and occurs within a maximum of 120 seconds. If the cause of the PAM Crypto Appliance shutdown is a temporary failure, it will be reset automatically. In case of hardware failure, the return will be manual;
- Hybrid Scenario with PAM Crypto Appliances and Virtual Appliances: Failover is done manually with synchronous automatic synchronization. In case of failure, the contingency environment will enter read-only mode, waiting for the manual failover to be done by the user or load-balancer rules;
- Hybrid Scenario with on-premise and cloud instances: Failover is done manually with synchronous automatic synchronization. In case of failure, the contingency environment will enter read-only mode, waiting for the manual failover to be done by the user or load-balancer rules;
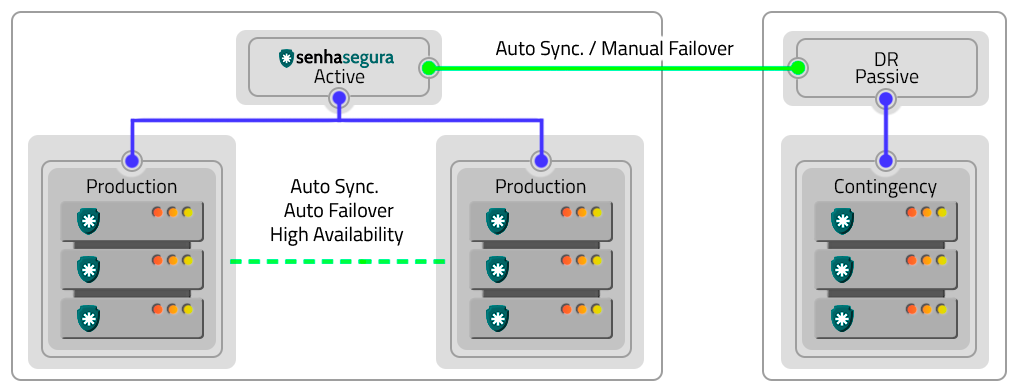
Active-Active
The Active-Active schema is a High Availability solution where multiple instances operate together, providing greater operational capacity and uninterruptible services.
By using this schema, the three applications will be active and in operation with synchronous automatic synchronization, executing processes in parallel. A load balancer will manage the distribution of work between the instances, besides ensuring the continuity of the service through the other instances, in case any of them stops working.
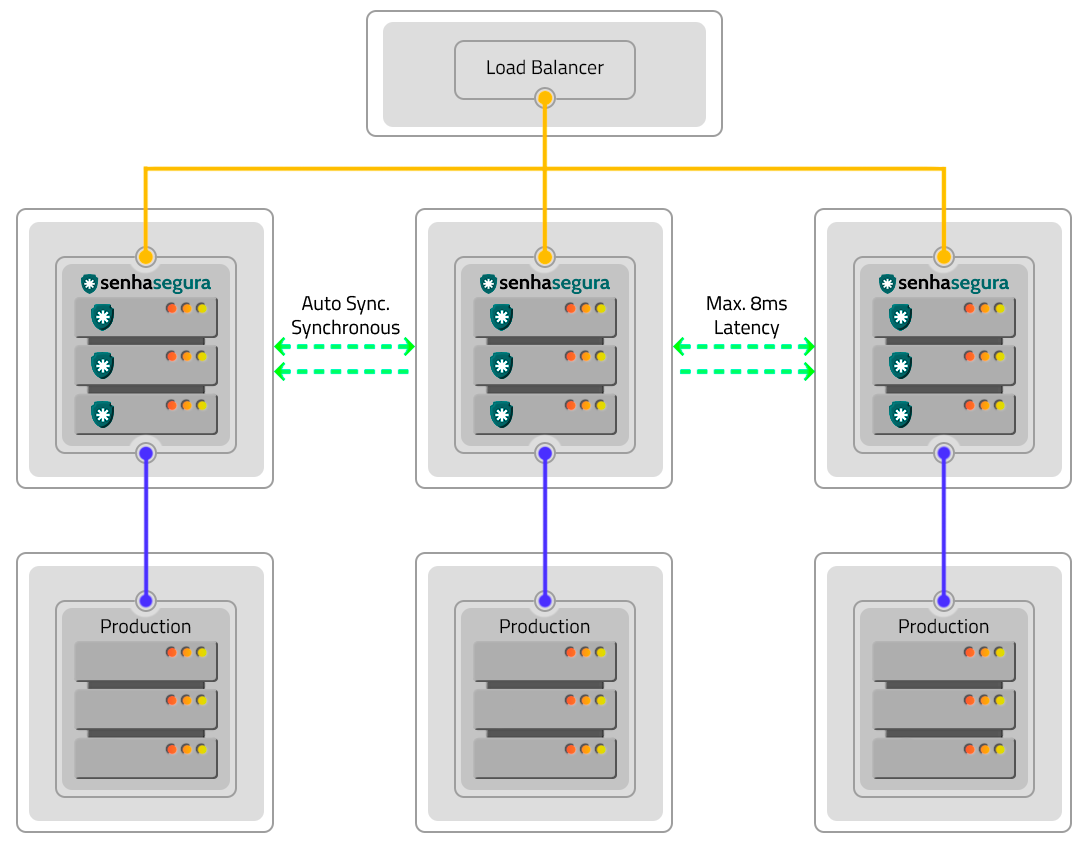
Disaster Recovery
The Active-Passive schema avoids cluster and site failures. To implement it, two clusters in different locations operating in the Active-Passive schema are required. Factors such as DR and production environments influence the configuration and operation in this way.
The difference in data will depend on the quality and speed of the links in relation to the volume of data generated by a cluster. If these variables are not appropriate, there may be data loss, production environment shutdown and DR environment activation. In case of hardware failures, resetting and returning occurs manually.
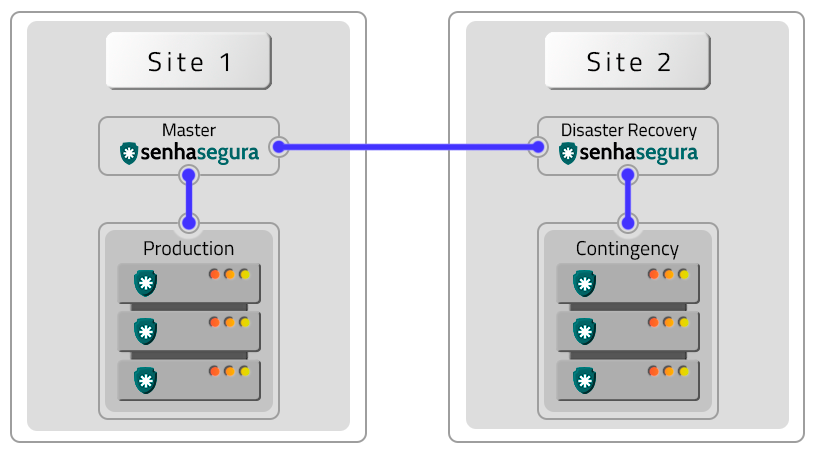
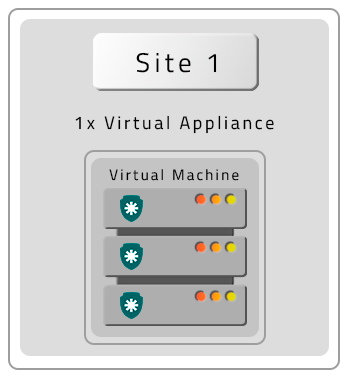
Homologated Architectures
All architectures bellow can be deployed into hybrid schemas using on-premisse datacenters and cloud providers services.
The following architectures are homologated by senhasegura :
A VM without Contingency (DR)
Two VMs with contingency location (DR)
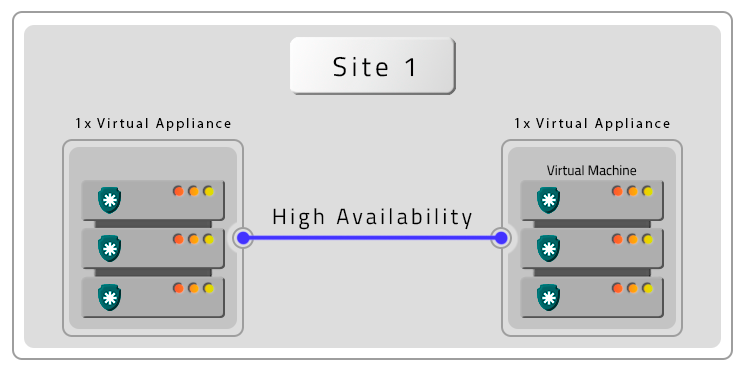
Two VMs with Remote Contingency (DR)
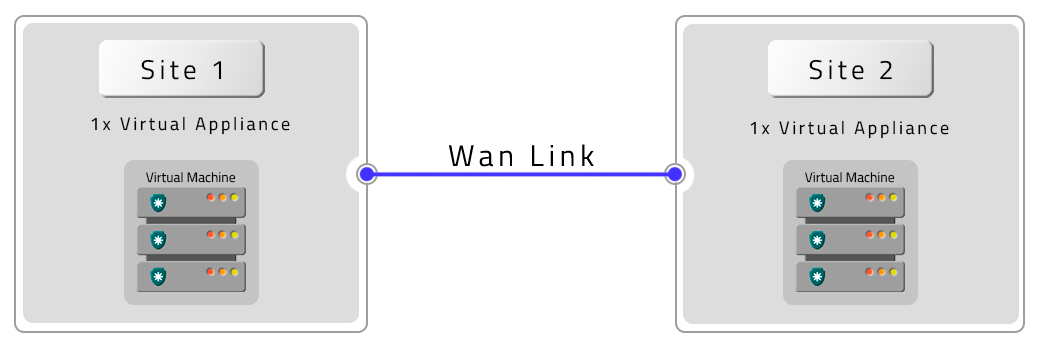
A PAM Crypto Appliance without Contingency (DR)

Two PAM Crypto Appliances in HA without contigency (DR)
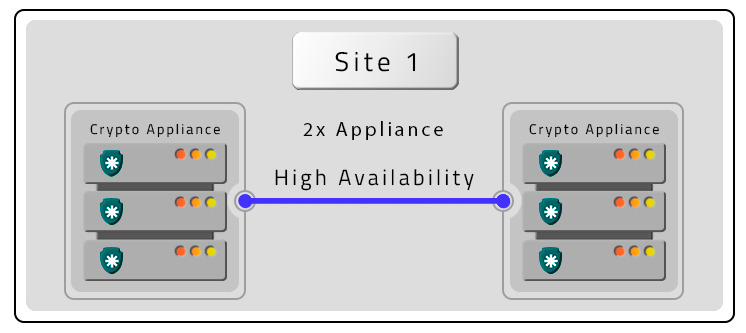
Three PAM Crypto Appliances in HA and Contigency (DR) without HA
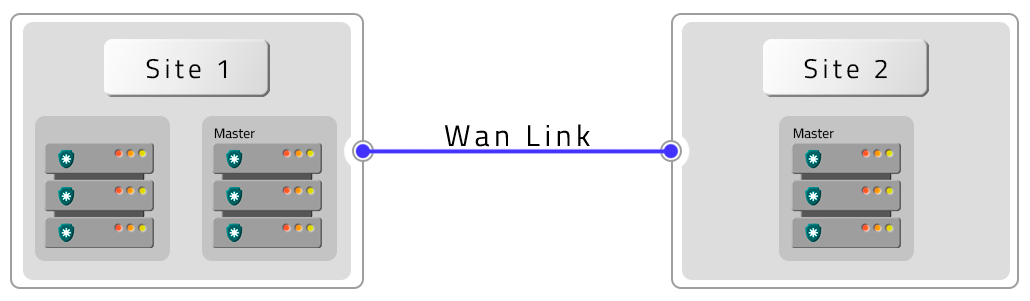
Four PAM Crypto Appliances in HA with HA Contigency (DR)
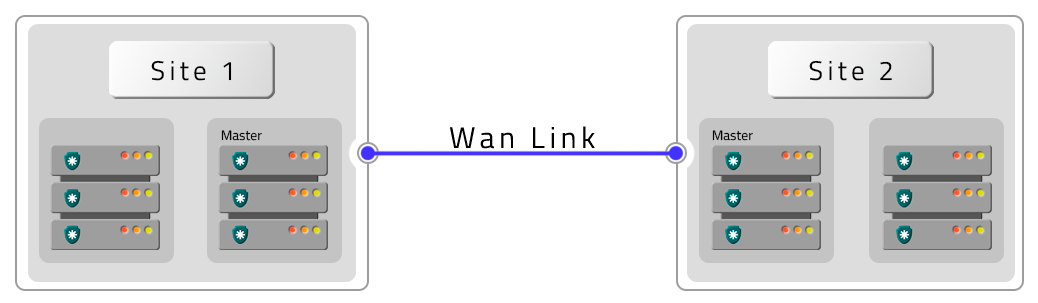
Six PAM Crypto Appliances with HA and two DR with HA
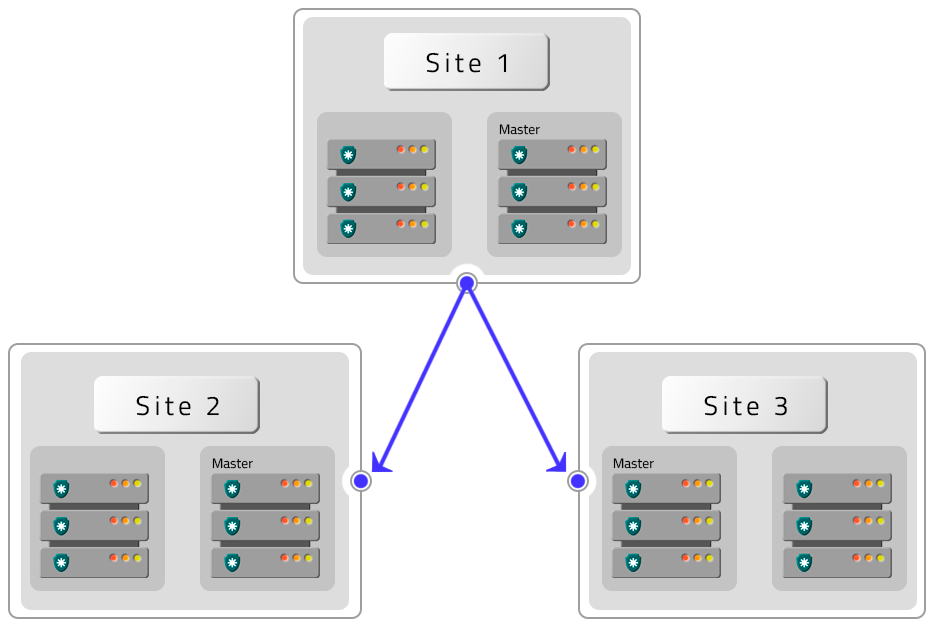
Four PAM Crypto Appliances with HA with two DR without HA
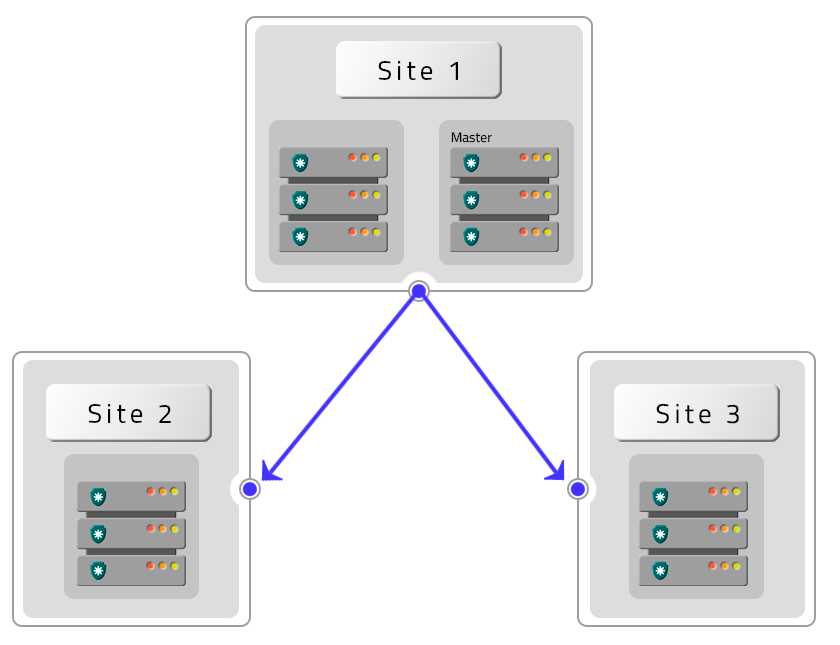
HA and DR replication features
The senhasegura architecture operates with two information bases: one, where the configurations are stored, and the other containing the logs and videos generated.
Configuring High Availability
To configure a High Availability cluster it is necessary that all instances of senhasegura are configured with the following premises:
- The activation license must be applied to all instances;
- All instances must be visible to each other through the network;
- TCP ports 22, 443, 3306, 4444, 4567, 4568, 9300 and UDP 4567 must be released between all instances;
- The backup drive must be visible to all instances;
- Only one unit should be active and with asynchronous services active;
- An instance will be chosen as Primary after the cluster creation process;
- Back up the data and get a snapshot of the instance as a guarantee back;
Having the premises resolved. All the rest of the operation can be executed through the Orbit Web interface.
Settings
During the configuration process of each instance, it will have its database restarted. It is extremely important that you wait for the instance to be restarted before you start configuring the next cluster member. Not respecting this time can lead the cluster to a split-brain scenario, where it will not be sure which information is most up-to-date among the instances. This scenario, although reversible, will increase the maintenance time.
To perform the configuration, go to the menu Orbit Config Manager ➔ Replication ➔ Settings. On this screen you will perform the following steps:
- Change the mode of operation from Standalone to Cluster;
- Enable the flag Enable replication
- Add the network IP of the first cluster member in the Primary member field;
- Add the network IP of other members in the following fields;
- Attention! The order of IPs registered as primary and other members must be replicated in all other instances!
- If members are in different datacenters, activate the flag Members are in different datacenters;
- In this case, also change the latency setting in the Latency between nodes field and its unique numeric identifier in the Network segment field;
- Add in the Recovery screen display message field a message that will be displayed to all users in case of cluster failure;
- Activate file synchronization with the Files flag if you want the files generated by one instance to be forwarded to the other instances using rsync;
- Click save to finish the operation;
View replication status
On this screen, you will see the status and operation of the instances through the generated logs and if errors occur:
In Orbit Config Manager ➔ Replication ➔ Status where we can visualize the instance situation with the following information:
Local server
Replication Status: Disabled/Enabled
Instance Type: Primary/Secondary
Operating mode: On/off
Last Sync: 12/18/2022 16:00:01
Authentication token: 85d4d3f2b2e3840179fa8327551690b6
If you have a remote server, you will have information about it as well.
View elasticsearch cluster status
This screen shows the status of the elasticsearch cluster service, located in the Orbit Config Manager ➔ Replication ➔ Elasticsearch module:
Data search cluster
Status: brings information about the instance's health.
Uuid: Universally unique identifier for the instance.
Size: the number of instances.
Master: is an identifier of the master instance in the cluster.
Version: shows which version this instance is in.
Shards: the amount of sharded data subset or pieces for a sharded cluster. Which together form all the data in the cluster.
State Uuid: Identifier of the state of the instance in the cluster.
Timed out: informs if an error occurred during the time and if the instance took a while to get a response from the cluster.
Cluster members
Index: is a unique identifier of the cluster instance's index.
Name: is the name of the cluster application.
Ephemeral: is an ephemeral identifier of the cluster instance.
Address: Shows the IP and Port of the instance.
Indexes
Name: brings the names of the logs that were generated by the instance.
Uuid Total: is a unique identifier referring to that generated log.
Size: is the size of the log that was generated by the system.
Health: This shows whether the log is working correctly.
Status: brings information about the instance's health.
Hot Spare - Automatic intances switch
senhasegura instances can be remotely activated and inactivated through HTTP requests that can be carried out from its load balancer. This control allows an instance that is under maintenance or unavailable for some reason, to be not considered in the load balancer redirection.
To configure IPs allowed to perform such query and operation, you must register the IP list in the Remote system activation field at the Orbit Config Manager ➔ Settings ➔ Recovery menu.
- At this screen, switch on the flag Allow system remote activation
- Fill the IP list allowed to execute automated requests at the field Allowed origin IPs to perform system remote activation
- Save the configuration clicking in Save button
You should realize this operation at every cluster members.
At this moment, these IPs can request the monitoring and administration URL
GET /flow/orbit/mntr. E.g.: https://mysenhasegura/flow/orbit/mntr.
The response will be the current instance state. It can be:
- HTTP 200: Application is enabled and available for user operation
- HTTP 403: Application is enabled but unavailable for user operation
- HTTP 451: Activation license is expired
- HTTP 503: Application is disabled
Thus, in a practical case, if the administrator inactivates the application of an instance, it begins responding HTTP 403 for the load balancer, which in turn will no longer forward traffic to that instance. As if any instance loses communication with other cluster members, and as consequence, make it database unavailable, this instance will respond HTTP 503 to the load balancer, which will no longer forward traffic for this instance.
Automatic instance activation and inactivation
Another interesting control is to allow an external system to control which instances should be activated and deactivated automatically. Imagine a scenario where the load on an entire network must be redirected to a contingency data center. The target datacenter instance must be active and ready to receive the requests, and the old production instance must lose its role as Master.
It is possible to switch between the instances roles through the activation/inactivation URL.
GET /flow/orbit/mntr/activate
Activates the instance to be used by users as long as the activation license is valid. If executed successfully, the instance that previously performed the role of Primary in the cluster, loses its relevance and this new instance receives the title of Primary. The other instances will not be automatically deactivated.
E.g.: https://mysenhasegura/flow/orbit/mntr/activate.
GET /flow/orbit/mntr/deactivate
Inactivates the instance to be used by users. If this instance is the Primary, it will be inactivated without electing any other member of the cluster as the new Primary. This action will also not activate other instances if they are inactive.
E.g.: https://mysenhasegura/flow/orbit/mntr/deactivate.
Always be in control of which instances are active and inactive in the cluster. Do not run the risk of accidentally inactivating all instances, causing an interruption in users' operations.