Alta Disponibilidade (HA) e Recuperação de Desastre (DR)
Os conceitos de HA+DR do senhasegura
A Alta Disponibilidade, ou High Availability (HA), pode ser classificada em duas categorias: Alta Disponibilidade de Hardware e Alta Disponibilidade de Aplicação.
Na Alta Disponibilidade de Hardware, existe uma conexão heartbeat entre os componentes de hardware senhasegura assegurando viradas para outro hardware caso um deles sofra indisponibilidade. Esta arquitetura foi desenhada para minimizar interrupções no senhasegura causadas por falhas de hardware, provendo continuidade de serviços através de componentes de alta redundância.
A recuperação de desastres envolve um conjunto de políticas e procedimentos que permitem recuperar a infraestrutura do senhasegura em caso de desastre, natural ou causado pelo homem. Ele habilita a redefinição dos recursos senhasegura em um ambiente alternativo quando não é possível recuperar o ambiente principal em um período de tempo razoável.
É possível implementar a arquitetura senhasegura usando:
PAM Crypto Appliances executando em datacenters on-premises;
PAM Virtual Appliances executando em datacenters on-premises;
PAM Virtual Appliances executando em provedores de nuvens;
Tecnologias de replicação
Há muitas camadas de replicação na arquitetura do senhasegura para garantir que todos os dados estarão disponíveis em todas as instâncias das senhasegura.
Replicação de banco de dados nativo
O senhasegura utiliza o MariDB Galera Cluster para conceder replicação de dados de banco de dados, configurado por padrão para suportar redes de alta latência;
Replicação do sistema de arquivo usando rsync
Todas as instâncias farão eco de seus arquivos entre todos os membros do cluster;
Replicação da camada do kernel
Ao trabalhar com a PAM Crypto Appliances, você também tem um DRBD implementado;
Features da Hot-Spare e Load balancer auto-fabricado
senhasegura tem instâncias de monitoramento e URLs administrativas para monitorar seu status que podem ser usadas pelos balanceadores de carga para mudar automaticamente as instâncias para um cenário de indisponibilidade.
Você pode usar um balanceador de carga proprietário ou adquirir o senhasegura Load-balancer em seu cenário de cluster. Veja mais no manual senhasegura Load-balancer .
Os URLs administrativos são melhor explicados na seção hotspare deste manual.
Ativo-Passivo
Você pode implementar o esquema Ativo-Passivo usando:
Dois PAM Virtual Appliances: O failover é feito manualmente com sincronização automática síncrona. Em caso de falha, o ambiente de contingência entrará em modo somente leitura, esperando que o failover manual seja feito pelo usuário ou pelas regras do load-balancer;
Dois PAM Crypto Appliances: Os dispositivos têm uma conexão de batimento cardíaco para detecção de falhas e seus próprios cabos de sincronização. Assim, quando é necessário que um dispositivo assuma o papel do outro, o processo é automático e ocorre dentro de um máximo de 120 segundos. Se a causa do desligamento do PAM Crypto Appliance for uma falha temporária, ele será reinicializado automaticamente. Em caso de falha de hardware, o retorno será manual;
Cenário hibrido com PAM Crypto Appliances e Virtual Appliances: O failover é feito manualmente com sincronização automática síncrona. Em caso de falha, o ambiente de contingência entrará em modo somente leitura, esperando que o failover manual seja feito pelo usuário ou pelas regras do load-balancer;
Cenário hibrido com on-premise e instâncias cloud: O failover é feito manualmente com sincronização automática síncrona. Em caso de falha, o ambiente de contingência entrará em modo somente leitura, esperando que o failover manual seja feito pelo usuário ou pelas regras do load-balancer;
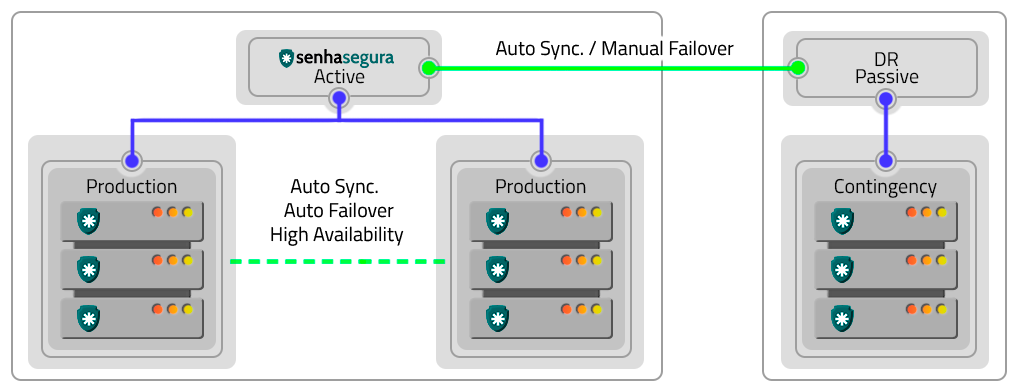
Ativo-Ativo
A forma Ativo-Ativo é uma solução de Alta Disponibilidade onde múltiplas instâncias senhasegura operam de forma conjunta, fornecendo maior capacidade de operação, além da ininterruptibilidade dos serviços.
Para implementar a forma Ativo-Ativo são necessárias, no mínimo, duas instâncias senhasegura , em Máquinas Virtuais ou em PAM Crypto Appliances.
Ao utilizar esta forma, as três aplicações estarão ativas e em operação com sincronização automática de forma síncrona, executando processos em paralelo. Um balanceador de carga gerenciará a distribuição de trabalho entre as instâncias, além de assegurar a continuidade do serviço através das demais instâncias, caso alguma venha a deixar de funcionar.
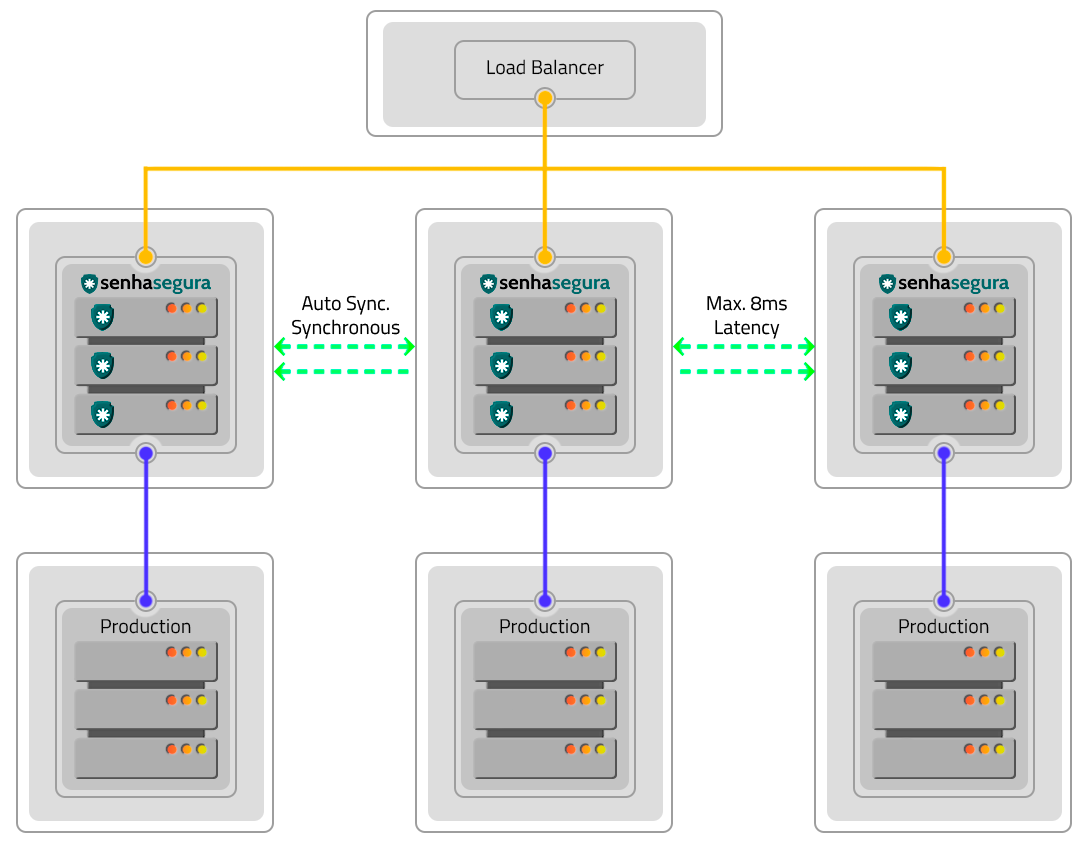
Disaster Recovery
A forma Ativo-Passivo evita falhas de cluster e local. Para implementá-lo, são necessários dois clusters em locais diferentes que operam no formulário Ativo-Passivo. Fatores como DR e ambientes de produção influenciam a configuração e operação desta forma.
A diferença nos dados dependerá da qualidade e velocidade dos links em relação ao volume de dados gerados por um cluster. Se essas variáveis não forem apropriadas, pode haver perda de dados, desligamento do ambiente de produção e ativação do ambiente de DR. No caso de falhas de hardware, a redefinição e o retorno ocorrem manualmente.
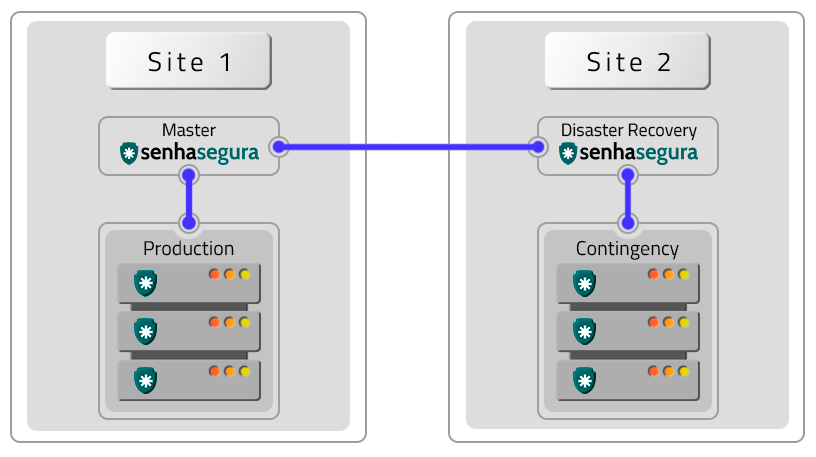
Arquiteturas Homologadas
Todas as arquiteturas abaixo podem ser implantadas em esquemas híbridos usando datacenters on-premisse e serviços de fornecedores de nuvens.
As arquiteturas a seguir são homologadas pelo senhasegura :
Uma VM sem contingência (DR)

Duas VMs com local de contingência (DR)

Duas VMs com contigência remota (DR)

Um PAM Crypto Appliance sem contigência (DR)

Dois PAM Crypto Appliances em HA sem contigência (DR)

Três PAM Crypto Appliances em HA e contigência (DR) sem HA

Quatro PAM Crypto Appliances em HA com contigência HA (DR)

Seis PAM Crypto Appliances com HA e dois DR com HA

Quatro PAM Crypto Appliances com HA com dois DR sem HA

Características de replicação HA e DR
A arquitetura do senhasegura opera com duas bases de informações: uma, onde são armazenadas as configurações, e outra contendo os logs e vídeos gerados.
Configurando a Alta Disponibilidade
Para configurar um cluster de Alta Disponibilidade é necessário que todas instâncias do senhasegura estejam configuradas com as seguintes premissas:
A licença de ativação deve estar aplicada a todas instâncias;
Todas instâncias devem estar visíveis uma a outra através da rede;
As portas TCP 22, 443, 3306, 4444, 4567, 4568, 9300 e UDP 4567 devem estar liberadas entre todas instâncias;
A unidade de backup deve estar visível a todas instâncias;
Apenas uma unidade deve estar ativa e com os serviços assíncronos ativos;
Uma instância será escolhida como Primária após o processo de criação do cluster;
Realize o backup dos dados e tenha um snapshot da instância como garantia de volta;
Tendo as premissas resolvidas. Todo restante da operação pode ser executado pela interface Orbit Web.
Configuração
Durante o processo de configuração de cada instância, ela terá seu banco de dados reiniciado. É extremamente importante que você aguarde o restabelecimento da instância antes de iniciar a configuração do próximo membro de cluster. Não respeitar este tempo pode levar o cluster a um cenário de split-brain, onde ele não terá certeza de quais informações estão mais atualizadas dentre as instância. Este cenário, apesar de reversível, irá elevar o tempo de manutenção.
Para realizar a configuração, vá ao menu Orbit Config Manager ➔ Replicação ➔ Configuração. Nesta tela você irá executar os seguintes passos:
Alterar o Modo de operação de Standalone para Cluster;
Ativar a flag Ativar replicação
Adicionar o IP de rede do primeiro membro do cluster no campo Membro primário;
Adicionar o IP de rede demais membros nos campos seguintes;
Atenção! A ordem de IPs registrados como primário e demais membros deve ser replicada em todas outras instâncias!
Caso os membros estejam em diferentes datacenters, ative a flag Membros estão em diferentes datacenters;
Neste caso, altere também a configuração de latência no campo Latência entre os membros e o seu identificador numérico único no campo Segmento de rede;
Adicione no campo Mensagem de exibição da tela de recovery uma mensagem que será exibida a todos usuários em caso de falha do cluster;
Ative a sincronização de arquivos com a flag Arquivos caso você deseje que os arquivos gerados por uma instância sejam encaminhados as demais instâncias utilizando rsync;
Clique em salvar para finalizar a operação;
Visualize o status da replicação
Nesta tela você vai visualizar através dos logs gerados o status e funcionamento das instâncias e caso ocorram erros:
Em Orbit Config Manager ➔ Replicação ➔ Status onde podemos visuzalizar a situação da instância e com seguintes informações:
Servidor local
Estado da replicação: Desativada/Ativada
Tipo de instância: Primária/Segundária
Modo de operação: Ativa/inativa
Última sincronização: 18/12/2015 16:00:01
Token de autenticação: 85d4d3f2b2e3840179fa8327551690b6
Caso tenha um servidor remoto terá informações dele também.
Visualizar status do cluster do elasticsearch
Esta tela mostra o status do serviço de cluster do elasticsearch, fica no módulo Orbit Config Manager ➔ Replicação ➔ Elasticsearch:
Data search cluster
Status: trás informações sobre o funcionamento da instância.
Uuid: é um identificador universalmente exclusivo da instância.
Size: é quantidade de instâncias.
Master: é um identificador da instância master no cluster.
Versão: mostra em qual versão esta instância se encontra.
Shards: é a quantidade de subconjunto de dados fragmentados ou partes para um cluster fragmentado. Que formam juntos todos os dados do cluster.
State Uuid: é um identificador do estado da instância no cluster.
Timed out: informa se ocorreu algum erro durante o tempo e se instância demorou para ter uma resposta do cluster.
Membros do cluster
Index: é um identificador único do index da instância do cluster.
Nome: é o nome da aplicação do cluster.
Ephemeral: é um identificador efêmero da instância do cluster.
Address: mostra o IP e a Porta da instância.
Indexes
Nome: trás os nomes dos logs que foram gerados pela instância.
Uuid Total: é um identificador único referente aquele log gerado.
Size: é o tamanho do log que foi gerado pelo sistema.
Health: mostra se o log está funcionando corretamente.
Status: trás informações sobre o funcionamento da instância.
Chaveamento automático de instâncias
As instâncias do senhasegura podem ser remotamente ativadas e inativadas através de requisições HTTP que podem ser realizadas a partir de seu load balancer. Este controle permite uma instância que esteja em manutenção, que esteja indisponível por algum motivo, não seja considerado no redirecionamento de cargas.
Para configurar IPs permitidos a realizar tal consulta e operação, você deve cadastrar a relação de IPs no campo Ativação remota do sistema do menu Orbit Config Manager ➔ Configurações ➔ Recovery.
Nessa tela, ative o indicador Permitir ativação remota do sistema
Adicione a relação de IPs permitidos a realizar a requisição no campo IPs de origem permitidos para ativação remota do sistema
Salve a operação com o botão Salvar
Realize essa operação em todos membros do cluster.
A partir deste momento, os IPs cadastrados poderão acessar a URL de monitoramento GET /flow/orbit/mntr. Ex: https://mysenhasegura/flow/orbit/mntr.
Essa URL irá responder o atual estado da instância. Podendo variar entre:
HTTP 200: Aplicação ativa e disponível para uso dos usuários
HTTP 403: Aplicação ativa mas indisponível para uso dos usuários
HTTP 451: Licença de ativação expirada
HTTP 503: Aplicação indisponível
Desta forma, em um caso prático, caso o administrador inative a aplicação de uma instância, esta passa a responder HTTP 403 para o load balancer, que por sua vez não irá mais encaminhar tráfego para essa instância. Assim como se alguma instância perder comunicação entre outros membros do cluster, e por conta disso, indisponibilizar o banco de dados, essa instância irá responder HTTP 503 ao load balancer, que não irá mais encaminhar tráfego para essa instância.
Ativação e inativação automática de instâncias
Outro controle interessante é permitir que um sistema externo controle quais instâncias devem ser ativadas e inativadas automaticamente. Imagine um cenário onde a carga de uma rede inteira deve ser redirecionada para um datacenter de contingência. É interessante que a instância deste datacenter alvo esteja ativo e pronto para receber a carga de requisições, e que a antiga instância de produção perca seu papel de principal.
Desta forma, é possível você realizar o chaveamento entre os papéis das instâncias através da URL de ativação/inativação.
GET /flow/orbit/mntr/activate
Realiza a ativação da instância para uso dos usuários desde que a licença de ativação esteja válida. Se executado com sucesso, a instância que antes executava o papel de Primária no cluster, perde sua relevância e esta nova instância recebe o título de Primária. As demais instâncias não serão inativadas automaticamente.
Exemplo: https://mysenhasegura/flow/orbit/mntr/activate.
GET /flow/orbit/mntr/deactivate
Realiza a inativação da instância para uso dos usuários. Caso essa instância seja a Primária, ela será inativada sem eleger nenhum outro membro do cluster como o novo Primário. Essa ação também não irá ativar as demais instâncias caso elas estejam inativas.
Exemplo: https://mysenhasegura/flow/orbit/mntr/deactivate.
Tenha sempre o controle de quais instâncias estão ativas e inativas no cluster. Não corra o risco de inativar todas instâncias acidentalmente, ocasionando uma interrupção nas operações dos usuários.